

| Public |
| Developers Home |
| Defects Reporting |
Streaming component combinatorsMario BlaževićSenior Software Developer Stilo International Ltd Keywords: streaming; markup; combinator; framework
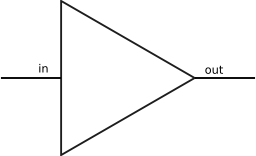
1 IntroductionStreaming, in the context of this paper, means processing data as it is being delivered. There are two reasons why streaming is important for markup processing. One is that streaming applications do not need to load their whole input into main memory at once, and hence achieve better performance and scalability compared to DOM and other technologies dependent on data-structure representations of the input. The other reason is that many applications are naturally expressed in producer-consumer or producer-filter-consumer patterns. The ability to express streaming makes these types of applications much easier to build. See [ Morrison 1994 ] for a more detailed justification of the streaming paradigm. Today's mainstream programming languages are unfortunately not particularly well-suited to the streaming model [ Wilmott 2003 ]. While it may be easy to implement a simple stream processor, its reuse in the context of a larger streaming application is quite difficult in comparison to the simple reuse of the native programming language concepts like functions or classes. Another way to support streaming is at the operating system level. Small, reusable streaming applications have traditionally been encouraged in the Unix environment [ Raymond 2003 ]. CMS Pipelines [ Hartmann 1992 ] provide support for more sophisticated streaming applications. At this level, however, the stream processors are treated as black boxes that cannot be type-checked, nor fused and optimized in other ways. The inter-process communication is also much more expensive than language-supported mechanisms would be. To summarize, neither the programming languages nor the operating systems provide a satisfactory glue logic for combining streaming components together. For these and other reasons, several attempts have been made to provide the missing support for streaming applications in the shape of a framework. To date, however, their impact has been limited. One reason for this state of affairs may be that existing frameworks are not modular enough. They provide various reusable components as well as glue logic needed to combine them into a pipeline. However, the generic components that the existing frameworks emphasize are filters. Two components in a filter class can be trivially combined together into a single filter component. There is no simple way to combine more complex components together. Some frameworks allow the user to combine components by connecting their ports together, but this style of component network specification is much more difficult to master than the simple pipelining of two filters. This paper is a proposal to introduce a new class of generic components that offers more potential for gluing than filters do, but at the same time remains easy to reason about. All components used in this paper, both basic and higher-level component combinators, have been implemented in OmniMark [ OmniMark 2006 ], version 8. Some of the component implementations have been omitted to conserve space. The same design could be replicated in other general-purpose programming languages. One likely constraint is that the implementation language should support coroutines in some form [ Wilmott 2003 ]. 1.1 Related workThe importance of streaming transformations of markup has long been recognized. There has been ongoing work on creating streaming implementations of standardized markup-processing and querying languages, XPath [ Peng 2005 ][ Olteanu 2004 ], XSLT and XQuery [ Florescu 2004 ] [ Fegaras 2002 ] among them. However, the design of these languages is such that no implementation can guarantee streaming behaviour. Other efforts have been focused on defining streaming subsets of the aforementioned languages, as well as specially-designed languages that fully support streaming processing, like OmniMark [ OmniMark 2006 ], Sequential XPath [ Desai 2001 ] and Streaming Transformations for XML [ Becker 2003 ]. Streaming component frameworks seem to have been reinvented several times. Most of these frameworks, however, are designed to work on coarse-grained filter components. Some examples are XPipe [ XPipe 2002 ], XML Pipeline [ XML Pipeline 2002 ], Cocoon [ Apache 2006 ], and iFlow [ Lui 2000 ]. Possible exceptions are STnG [ Krupnikov 2003 ], as well as THREADS [ Morrison 1994 ] which can apply components to arbitrary parts of the framework input. However, none of the listed frameworks seem to try to formally classify the components into abstract classes, nor define any generic component combinators that would operate on instances of component classes. On the other hand, plenty of work has been done on combinator frameworks in general, especially in the functional programming language community. The parser component combinators [ Hutton 1996 ] are closely related to this work. A nice implementation of a parser combinator library is Parsec [ Leijen 2001 ]. The main difference between a parser combinator framework and a streaming component combinator framework, such as the one presented here, is that parser frameworks are streaming only on their input side. On the output side, they produce a well-defined and structured result from the input source, typically a parse tree. This is possible only because a parser deals with highly structured and constrained input. Once some input is parsed and the result constructed, the input is no longer necessary. In contrast, a streaming component combinator framework has to deal with input that is only weakly structured; in many cases the only meaningful result of processing any single component is just a rearrangement of the component's input. There are also combinator frameworks for XML document processing, HaXML [ Wallace 1999 ] for example. While many of the combinators defined by HaXML resemble ours, there are two important differences: HaXML combinators operate exclusively on filters and ad hoc Haskell function types, and HaXML operates on a parsed document tree and therefore is not streaming. The latter constraint appears to be shared by all XML combinator frameworks implemented in Haskell today. The XPath implementation in Scheme, SXPath [ Lisovsky 2003 ], provides combinators that operate on nodeset-transforming functions, which are also not designed for streaming. The most recent work [ Shivers 2006 ] finally applies the combinator approach to streaming components by using continuation passing to transfer control. The early results are promising, but most attention is still devoted to simple linear pipelines of filter components. 2 Streaming component types2.1 FiltersA filter is a streaming component with one data source and one data sink. The concept of streaming filter components has been recognized for some time, and is a part of programmers' vocabulary in many areas. A filter component takes a data stream as its input, transforms it, and produces another data stream as its output. The best-known example of filters is probably the Unix piping model [ Raymond 2003 ]. A filter component has a responsibility to consume its whole input. It is not allowed to simply terminate in the middle of processing of its input. If one filter in a pipeline terminates, the whole pipeline dies with it. In OmniMark, a filter component can be represented as an abstract data type with a single operation apply-filter, illustrated below in figure 1: A concrete filter implementation must extend the abstract filter type and override its apply-filter method. Several concrete filter examples are given next. 2.1.1 Basic filters
2.1.2 Markup filtersThe filters listed in the previous section are generic, in the sense that they can be applied to any form of character input stream. But if we restrict our attention to inputs in a particular format, we can provide many more interesting filters. The more specific the input is, the more sophisticated the possible processing components can get. For example, we can apply the following filters to any input in XML format:
The inputs and outputs of XML-specific components are not well-formed XML documents, but rather streams of well-formed mixed content. 2.1.3 Buffering filtersThere is a large class of filters that have to buffer their whole input before they can produce any result. These are not streaming components in any sense, but since they expose their functionality through a streaming interface they can still be used in a streaming component framework. The trick is to restrict their usage to the parts of the stream which must be processed in this way. Unfortunately, the burden of deciding which parts those are is on the user.
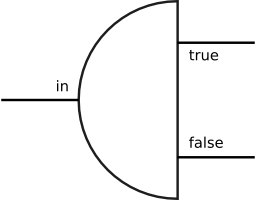
2.2 SplittersA splitter is a streaming component with one data source and two sinks. A pure splitter component is not supposed to modify its input in any way; instead, it streams portions of its input stream to either of its two outputs. Every bit from the input stream has to be present in one or the other of the output streams. Secondly, the outputs have to be properly interleaved. Another way of stating the invariants is to say that if the two sinks of any pure splitter are connected together, the component acts as an identity transform. The concept of splitters, together with the operations that can be applied to them, is the only new technical contribution this paper has to offer. The streaming component frameworks have been researched and built before, but the emphasis has mostly been on filters. That is not to say that no framework contained splitter components before. The previous work on streaming pipeline frameworks has mostly seen splitters as large, ad hoc components that must be provided by the user. In OmniMark, a splitter component can be represented as an abstract data type with a single operation split that takes one data source and two sinks as arguments:
The concrete splitter instances must extend the base splitter type and override the method split. In the examples that follow, the OmniMark code will be elided for brevity. 2.2.1 Basic splitters
2.2.2 Markup splittersThe observation on the generic and purpose-specific filters also holds true for splitters: as we restrict the inputs to be more specific, the splitters we can apply to them become more sophisticated.
3 Streaming component combinatorsA library of streaming components like those listed in the previous section can help perform various basic tasks, but we call them components because the goal is to use them together as building blocks for assembling more sophisticated stream-processing tools. One way to combine streaming components is to wire their ports together; for examples see [ Morrison 1994 ] and [ XML Pipeline 2002 ]. This method directly corresponds to the way pipelines are usually represented graphically, by drawing lines between components' ports. While a specification written in this style can express any possible configuration of components, the technique does not scale well: the number of possible connections grows as the square of the number of all ports of all components present in the network. The other common approach is to use combinators. Component combinators operate on whole components instead of their ports, much in the same way that combinatory logic [ Curry 1958 ] operates on whole functions instead of their arguments and results. An example of this specification method in streaming frameworks is [ Krupnikov 2003 ], but the best known streaming combinator is the Unix pipe operator. While the wiring approach is applicable to any number of components of any kind, a combinator can be applied only to specific kinds of components. This constraint leads to two design imperatives:
The framework presented here classifies all components into two classes: filters and splitters. Every basic component is either a splitter or a filter, the only arguments of every combinator are splitters and filters, and the result of each combinator application is either a filter or a splitter component. 3.1 Filter combinators
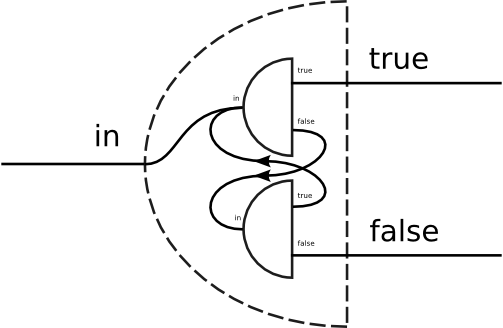
3.2 Pseudo-logical splitter combinatorsA pure splitter component can be thought of as a representation of a logic predicate. The portion of the input that the splitter sends to one of its two sinks is taken to satisfy the predicate, and the input that goes to its other sink does not. Having this picture in mind, the following splitter combinators become obvious.
Note that the >& and >| operators are not exact equivalents of the corresponding Boolean and/or operators. In particular, they are commutative only when their two argument splitters agree on what forms a unit of input, i.e., when the input stream is a uniform sequence of records. Most markup splitters do not satisfy this property. For example, the expression xml-element-named "A" >& xml-element-content >& xml-element-named "B" is an equivalent of the XPath expression A/B, which is obviously not commutative. 3.3 Flow-control combinatorsSince approximating a splitter as a logic predicate ( i.e., a boolean expression) turned out to be productive, we can try digging deeper into our intuition for useful metaphors. For example, we can see a filter component as an imperative statement. A filter modifies the stream that flows through it, much like an imperative statement that modifies the state surrounding it. The piping operator >> would then be an equivalent of a statement sequencing operator. Having both imperative statements and Boolean expressions, the natural thing to look for next would be an equivalent of the flow-control statements.
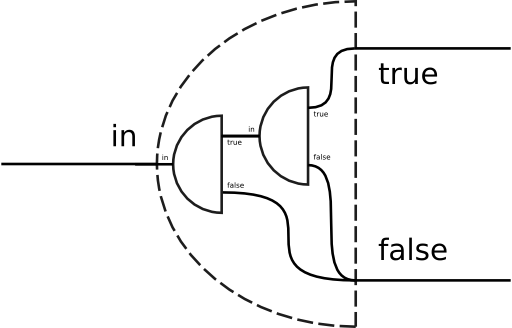
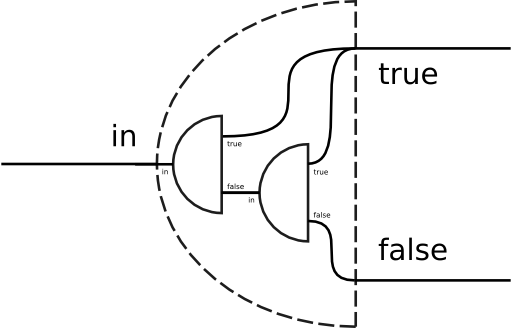
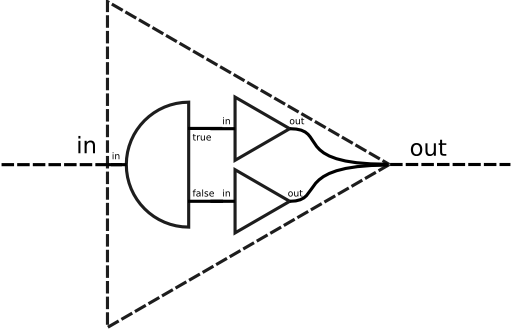
The combinators where and unless are simpler versions of the if combinator, having one of the two filters be as-is. The select combinator uses the as-is and suppress filters as the true and false sinks, respectively. In effect, the select combinator converts a splitter into a filter which retains only the true portion of the input. The three combinators can be more formally defined as follows:
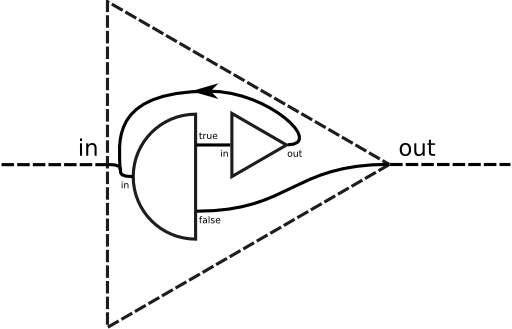
A combinator language is point-free by definition, so we cannot use component names or labels to achieve looping and recursion. If we want our component networks to be able to form loops, we need more flow-control combinators.
3.4 Active combinatorsEach of the combinators defined so far builds a streaming network out of its argument components, and then lets the network do its job. The combinator itself plays no role after the initial configuration. This property guarantees that the combinator is completely generic: the type of input that can be processed by the network is constrained only by its components, not by the combinators applied to them. The combinators defined next are different; they are still generic enough to be used on any kind of input, but they also actively process the input stream. They achieve these seemingly contradictory goals by using their splitter argument to determine the structure of the input. Every contiguous portion of the input that gets passed to one or the other sink of the splitter is treated as one section in the logical structure of the input stream. What is done with the section depends on the combinator, but the sections, and therefore the logical structure of the stream, are determined by the argument splitter alone.
Note that the combinators having and having-only must buffer each complete chunk of input until the second splitter tests it.
One reason buffering matters is that flow-control
combinators require their argument components to agree on
which parts of the stream get buffered and at which point
they get flushed. If one of the subcomponents buffers a part
of its input and the other does not, the output of the
combined component may be improperly interleaved. The
following filter expression is one such example:
4 ExamplesLet us try to define some higher-level components as a test of the framework's expressivity.
5 Conclusion and future workWe have demonstrated that the concept of splitter and filter components, coupled with the power of generic component combinators, is expressive enough to build new filters and new splitters from a small base of predefined basic components and component combinators. In the future, we hope to use the presented framework in real-world applications. More practice is needed to grow the library of basic components and combinators. We can see that all components communicate with each other through simple data streams, with no out-of-bounds control signals whatsoever. While this feature of the framework simplifies manipulation and reasoning about the component networks, it is a constraint in some cases. In particular, one must take care when using buffering components: If they disagree on the structure of the input stream the output of the network can be improperly interleaved. A solution that could discover a problem of this kind by a static analysis of the component network would be greatly preferable to synchronization signals. Another area of research would be concerned with various transformations of the component networks. One possibility is automatic conversion of XPath and XQuery expressions into a streaming component representation. At the other end, a built-up component pipeline, or at least parts of it, could be compiled into more efficient code in OmniMark or another host language. And in between, the component network could be transformed either at the high level, using a graph rewriting system, or at the lower level, by fusing multiple components into a single one. Though the current implementation is in OmniMark, the only features the framework requires from the implementation language are abstract data types and some form of coroutine support. One interesting possibility would be to implement the same framework in Haskell, since the existing implementations of parser combinator libraries in Haskell have proven quite successful. AcknowledgmentsI want to thank Jacques Légaré for his comments, Helen St. Denis, Joe Gollner and Norbert Winklareth for finding the time to read the paper, and the rest of the team at Stilo for providing the initial motivation for the work. Bibliography[ Morrison 1994 ] John Paul Morrison, Flow Based Programming, Van Nostrand Reinhold, 1994. [ Wilmott 2003 ] Sam Wilmott, What programming language designers should do to help markup processing, Extreme Markup Languages, 2003
[
Raymond 2003
]
Eric Steven Raymond, The Art of Unix
Programming,
[
Hartmann 1992
]
John P. Hartmann, IBM Denmark, CMS
Pipelines Explained
[
OmniMark 2006
]
OmniMark language
documentation,
[ Peng 2005 ] Feng Peng, Sudarshan S. Chawathe, XSQ: A streaming XPath engine, ACM Transactions on Database Systems (TODS), 30:2, 2005. [ Olteanu 2004 ] Dan Olteanu, Tim Furche, François Bry, An efficient single-pass query evaluator for XML data streams, Proceedings of the 2004 ACM symposium on Applied Computing627 - 631, 2004. [ Florescu 2004 ] Daniela Florescu, Chris Hillery, Donald Kossmann, Paul Lucas, Fabio Riccardi, Till Westmann, J. Carey, Arvind Sundararajan, The BEA streaming XQuery processor, The VLDB Journal 13:3, 2004. [ Fegaras 2002 ] Leonidas Fegaras, David Levine, Sujoe Bose, Vamsi Chaluvadi, XML query processing: Query processing of streamed XML data, Proceedings of the eleventh international conference on Information and knowledge management, 2002. [ Desai 2001 ] Arpan Desai, Introduction to Sequential XPath , XML 2001.
[
Becker 2003
]
Oliver Becker, Extended SAX Filter
Processing with STX,
[
XPipe 2002
]
XPipe presentation at XML SIG
NY,
[
XML Pipeline 2002
]
XML Pipeline Definition Language
Version 1.0 ,
[
Apache 2006
]
[ Lui 2000 ] Andrew Kwok-Fai Lui, Mark W. Grigg, Michael J. Owen, T. Andrew Au, iFlow (poster session): a data streaming application framework based on a uniform abstraction, Addendum to the 2000 proceedings of the conference on Object-oriented programming, systems, languages, and applications (Addendum), 2000. [ Krupnikov 2003 ] K. Ari Krupnikov, STnG - a Streaming Transformations and Glue framework, Extreme Markup 2003. [ Hutton 1996 ] Graham Hutton, Erik Meijer, Monadic Parser Combinators, Technical report NOTTCS-TR-96-4. Department of Computer Science, University of Nottingham, 1996.
[
Leijen 2001
]
Daan Leijen, Parsec, a fast combinator parser,
[ Wallace 1999 ] Malcolm Wallace, Colin Runciman, Haskell and XML: Generic Combinators or Type-Based Translation?, International Conference on Functional Programming, 1999. [ Lisovsky 2003 ] Kirill Lisovsky, Dmitry Lizorkin, XML Path Language (XPath) and its functional implementation SXPath, Russian Digital Libraries Journal, Year 2003, Issue 4 [ Shivers 2006 ] Olin Shivers, Matthew Might, Continuations and Transducer Composition, PLDI 2006. [ Curry 1958 ] HB Curry, R Feys, W Craig, Combinatory logic, North-Holland, 1958. |
||||||||||||||||
OmniMark, the OmniMark swirl logo and Stilo are registered trademarks of Stilo International Ltd. All rights reserved.